Explorando diferentes modos de ver
Redes de rótulo x espaços vetoriais
A proposta da atividade é fomentar o olhar cético e crítico em relação às metodologias digitais para análises de acervos visuais, estimulando a imaginação metodológica e a postura científica diante de abordagens experimentais e exploratórias mediadas por modelos de visão computacional. O exercício consiste em comparar criticamente dois procedimentos recorrentes de análise de grandes corpora visuais: análise de redes de rótulos descritores de imagem e exploração de agrupamentos por semelhança de características computacionais. O primeiro traduz as imagens em rótulos semânticos gerados por um sistema de visão computacional e organiza essas relações em forma de rede. O segundo traduz as imagens em vetores numéricos extraídos de uma arquitetura convolucional e projeta esse espaço de similaridade em duas dimensões. Em ambos os casos, o corpus é o mesmo. O que muda é o regime de representação mobilizado para tornar o conjunto legível: no primeiro, a imagem aparece mediada por descritores linguísticos; no segundo, por proximidade vetorial entre features visuais. O objetivo é observar como diferentes escolhas metodológicas produzem distintas formas de ver e analisar um mesmo acervo.
A atividade utiliza a base Concepts iStockphoto 1k, um conjunto supervisionado de imagens organizado por conceitos amplos estabelecidos pela plataforma. As imagens foram coletadas no iStockphoto por meio de buscas separadas por categoria conceitual, com filtro para imagens contendo 1, 2 ou mais pessoas; a opção sem pessoas foi excluída. Os metadados foram extraídos com o Instant Data Scraper, salvos em CSV, e as imagens foram baixadas posteriormente usando o MOODIE Grabber. Depois, os arquivos foram renomeados com um identificador único seguido do nome da categoria, para facilitar a organização e a inspeção visual do acervo. Todas as imagens foram processadas e classificadas com rótulos do Google Vision API 2024.
A base original continha 21.999 imagens, distribuídas em 11 categorias, e passou por extração automática de atributos com a Google Vision API em 17/06/2024. Para esta versão analítica, foi realizado um sampleamento aleatório balanceado, resultando em uma base final de 1.000 imagens distribuídas da seguinte maneira:
- lgbtqia: 91 imagens (9,1%)
- social movement and politics: 91 imagens (9,1%)
- professionals: 91 imagens (9,1%)
- leisure: 91 imagens (9,1%)
- pets: 91 imagens (9,1%)
- travel and vacation: 91 imagens (9,1%)
- food drink: 91 imagens (9,1%)
- family: 91 imagens (9,1%)
- kids and children: 91 imagens (9,1%)
- health care: 91 imagens (9,1%)
- upscale fashion and beauty: 90 imagens (9,0%)
O material foi preparado como suporte didático para uso exclusivo na disciplina Visualidades Algorítmicas, vinculada ao PPGCI-ECA-USP, no semestre 2026.1, ministrada pelo professor Dr. Elias Bitencourt. Não é permitido utilizar esses dados em pesquisas ou publicações sem autorização prévia do autor.
Vision Labels Network
Na etapa Vision Labels Net, as 1.000 imagens e os respectivos rótulos semânticos (labels) obtidos pela Google Vision API (2024) foram usados para construir uma rede com dois tipos de nós (bipartida) — imagens e rótulos. Sempre que um rótulo é atribuído a uma imagem, uma aresta é desenhada entre eles. Nesse tipo de abordagem, a relação entre imagens é mediada por descritores semânticos que resultam dos modelos de visão usados na Google Vision API.
A espacialização da rede foi realizada no Gephi Light com o algoritmo ForceAtlas2 (Jacomy, Venturini, Heymann, Bastian; 2014), usando Barnes-Hut theta = 0,5, edge weight influence = 1 e gravity = 0,05 com Strong Gravity Mode ativado. A configuração foi executada sem LinLog mode e sem outbound attraction distribution, com scale ratio = 20 e slowdown = 8,510430556378006. Em termos visuais, isso produz uma rede mais contínua, com contenção da dispersão e manutenção da força atrativa dos nós mais conectados.
Depois da espacialização, foi aplicada a detecção de comunidades com o algoritmo Louvain, usando resolution = 1. Esse procedimento identifica grupos de nós mais densamente conectados entre si.
Para exploração didática, a rede final foi exportada para o NODIE, ferramenta desenvolvida no Datalab Design/UNEB para análise interativa de redes. O Nodie cria um dashboard interativo que permite inspecionar nós, métricas, buscar por termos e visualizar padrões nas relações entre imagens de maneira mais intuitiva e sem depender diretamente da interface do Gephi.
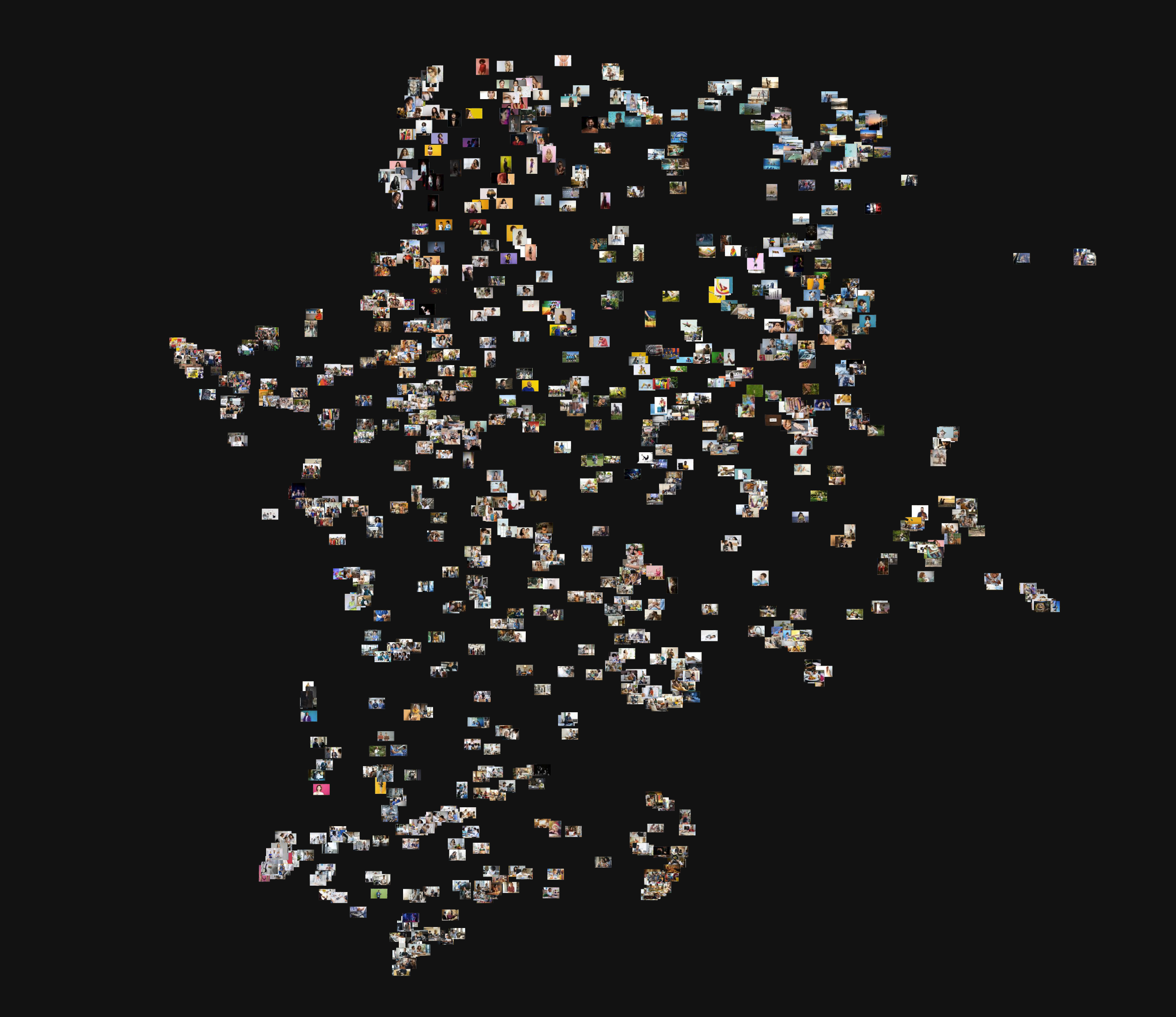
Pixplot
O mesmo corpus foi processado no PixPlot, ferramenta desenvolvida no Yale Digital Humanities Lab para exploração interativa de grandes coleções de imagens em espaços bidimensionais. Diferentemente da rede de rótulos, o PixPlot não organiza o acervo a partir de descritores linguísticos gerados por uma API. Ele compara as imagens com base em representações numéricas extraídas diretamente de seus padrões visuais, produzidas por uma rede neural pré-treinada.
O modelo usado para essa extração foi o InceptionV3, a partir da camada avg_pool. Em vez de classificar cada imagem por um rótulo final, esse procedimento gera uma representação numérica compacta que sintetiza padrões visuais aprendidos pelo modelo durante seu treinamento em ImageNet. A relação entre as imagens, nesse caso, passa a ser calculada pela proximidade entre essas representações vetoriais.
Após a extração das características visuais, essas representações numéricas precisam ser reduzidas e reorganizadas para que o acervo possa ser explorado em um espaço bidimensional e para que regiões de maior concentração visual se tornem perceptíveis. Para isso, o PixPlot combinou PCA e UMAP. O PCA foi usado como etapa inicial de redução, condensando os vetores em suas variações mais relevantes. Em seguida, o UMAP projetou esse espaço em duas dimensões, procurando preservar relações de proximidade e distância entre imagens visualmente semelhantes. Nessa etapa, foi usada a métrica de correlação (metric = correlation), que compara os vetores pelo padrão de variação entre suas características.
Para destacar os hotspots, o PixPlot utilizou HDBSCAN, um algoritmo de agrupamento não supervisionado que identifica regiões mais densas do espaço visual sem exigir classificação prévia das imagens. No processamento desta base, foram usados min_cluster_size = 9 e limite de 14 clusters em destaque na interface.